Keşifsel veri analizi
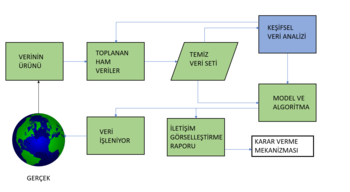
İstatistikte, keşifsel veri analizi (exploratory data analysis; EDA), genellikle istatistiksel grafikler ve diğer veri görselleştirme yöntemlerini kullanarak temel özelliklerini özetlemek için veri kümelerini analiz etme yaklaşımıdır. İstatistiksel bir model kullanılabilir veya kullanılamaz. Ancak öncelikle EDA, verilerin bize resmi modelleme veya hipotez testi görevinin ötesinde neler söyleyebileceğini görmek için vardır. Keşifsel veri analizi, istatistikçileri verileri keşfetmeye ve muhtemelen yeni veri toplama ve deneylere yol açabilecek hipotezler formüle etmeye teşvik etmek için John Tukey tarafından desteklenmiştir. EDA, model uydurma ve hipotez testi için gereken varsayımları daha dar bir şekilde kontrol etmeye ve eksik değerleri ele almaya ve gerektiğinde değişkenlerin dönüşümlerini yapmaya odaklanan ilk veri analizinden (initial data analysis; IDA)[1] farklıdır. EDA, IDA'yı kapsamaktadır.
Tarihçe
Birçok EDA fikri daha önceki yazarlara kadar izlenebilir, örneğin:
- Francis Galton, sipariş istatistiklerini ve niceliklerini vurguladı.
- Arthur Lyon Bowley, stemplot'un öncüllerini ve beş sayı özetini kullandı (Bowley, ortanca ile birlikte uç noktalar, ondalık sayılar ve çeyrekler dahil olmak üzere aslında "yedi haneli bir özet" kullandı - bkz. İlk İstatistik El Kitabı (3. baskı, 1920).), sayfa 62[2]– "maksimum ve minimum, medyan, çeyrekler ve iki ondalık" "yedi pozisyon" olarak tanımlar.
- Andrew Ehrenberg bir veri azaltma felsefesi dile getirdi.[2]
Açık Üniversite'nin Toplumda İstatistik (MDST 242) dersi, yukarıdaki fikirleri aldı ve bunları Gottfried Noether'in yazı tura ve medyan testi yoluyla istatistiksel çıkarımlar sunan çalışmasıyla birleştirdi.
Genel bakış
Tukey, 1961'de veri analizini şu şekilde tanımladı: "Verileri analiz etme prosedürleri, bu tür prosedürlerin sonuçlarını yorumlama teknikleri, analizini daha kolay, daha kesin veya daha doğru hale getirmek için veri toplamayı planlama yolları ve verilerin analizi için geçerli olan (matematiksel) istatistiklerin tüm makineleri ve sonuçları."[3]
Tukey'nin EDA'yı savunması, istatistiksel hesaplama paketlerinin, özellikle de Bell Laboratuvarlarında S'nin geliştirilmesini teşvik etti. S programlama dili, S-PLUS ve R sistemlerine ilham verdi. Bu istatistiksel hesaplama ortamları ailesi, istatistikçilerin daha fazla çalışmayı hak eden verilerdeki aykırı değerleri, eğilimleri ve kalıpları belirlemesine olanak tanıyan büyük ölçüde geliştirilmiş dinamik görselleştirme yeteneklerine sahiptir.
Tukey'nin EDA'sı istatistiksel teorideki diğer iki gelişmeyle ilgiliydi: her ikisi de istatistiksel modellerin formüle edilmesinde istatistiksel çıkarımların hatalara duyarlılığını azaltmaya çalışan sağlam istatistikler ve parametrik olmayan istatistikler. Tukey, sayısal verilerin beş sayı özetinin (iki uç (maksimum ve minimum), medyan ve çeyrekler) kullanımını teşvik etmiştir. Çünkü bu medyan ve çeyrekler, deneysel dağılımın işlevleri olan, ortalama ve standart sapma; dahası, çeyrekler ve medyan, geleneksel özetlerden (ortalama ve standart sapma) çarpık veya ağır kuyruklu dağılımlara karşı daha dayanıklıdır. S, S-PLUS ve R paketleri, parametrik olmayan ve sağlam (birçok problem için) Quenouille ve Tukey'nin jackknife[4] ve Efron'un önyüklemesi gibi yeniden örnekleme istatistiklerini kullanan rutinleri içeriyordu.
Keşfedici veri analizi, sağlam istatistikler, parametrik olmayan istatistikler ve istatistiksel programlama dillerinin geliştirilmesine yarar sağlamıştır. Ayrıca istatistikçilerin bilimsel ve mühendislik problemleri üzerindeki çalışmalarını kolaylaştırmıştır. Bu tür problemler, yarı iletkenlerin üretimini ve Bell Laboratuvarlarını ilgilendiren iletişim ağlarının anlaşılmasını içeriyordu. Tümü Tukey tarafından desteklenen bu istatistiksel gelişmeler, istatistiksel hipotezleri test etmeye yönelik analitik teoriyi, özellikle de Laplacian geleneğinin üstel ailelere yaptığı vurguyu tamamlamak üzere tasarlanmıştır.[5]
Geliştirme
John W. Tukey, 1977'de Keşif Verileri Analizi kitabını yazdı.[6] Tukey, istatistikte çok fazla vurgunun istatistiksel hipotez testine (doğrulayıcı veri analizi) verildiğine karar verdi; test edilecek hipotezler önermek için verilerin kullanılmasına daha fazla vurgu yapılması gerekiyordu. Özellikle, iki tür analizin karıştırılmasının ve bunların aynı veri kümesi üzerinde kullanılmasının, veriler tarafından önerilen hipotezleri test etmenin doğasında bulunan sorunlar nedeniyle sistematik önyargıya yol açabileceğini savundu.
EDA'nın amaçları şunlardır:
- Gözlenen fenomenin nedenleri hakkında hipotezler önermek
- İstatistiksel çıkarımın dayandırılacağı varsayımları değerlendirmek
- Uygun istatistiksel araç ve tekniklerin seçimini desteklemek
- Anketler veya deneyler yoluyla daha fazla veri toplanması için bir temel sağlamak[7]
Veri madenciliğinde birçok EDA tekniği benimsenmiştir. Ayrıca genç öğrencilere istatistiksel düşünceyi tanıtmanın bir yolu olarak öğretilmektedir.[8]
Teknikler ve araçlar
EDA için yararlı olan bir dizi araç vardır. Ancak EDA, belirli tekniklerden çok, alınan tutumla karakterize edilir.[9]
EDA'da kullanılan tipik grafik teknikleri şunlardır:
- Kutu grafiği
- Histogram
- Çok değişkenli grafik
- Akış Çizelgesi
- Pareto grafiği
- Dağılım grafiği
- Kök-yaprak grafiği
- Paralel koordinatlar
- Olasılık oranı
- Hedeflenen projeksiyon takibi
- PhenoPlot[10] ve Chernoff yüzleri gibi glif tabanlı görselleştirme yöntemleri
- Büyük tur, rehberli tur ve manuel tur gibi projeksiyon yöntemleri
- Bu planların etkileşimli versiyonları
Boyutsal küçülme:
- Çok boyutlu ölçekleme
- Temel bileşen analizi (PCA)
- Çok Doğrulu PCA
- Doğrusal olmayan boyut azaltma (NLDR)
Tipik nicel teknikler şunlardır:
- Median polish
- Trimean
- Ordination
Yazılım
- JMP, SAS Enstitüsünden bir EDA paketi.
- KNIME, Konstanz Information Miner – Eclipse tabanlı Açık Kaynaklı veri keşif platformu.
- Orange, açık kaynaklı bir veri madenciliği ve makine öğrenimi yazılım paketi.
- Python, veri madenciliği ve makine öğreniminde yaygın olarak kullanılan açık kaynaklı bir programlama dilidir.
- R, istatistiksel hesaplama ve grafikler için açık kaynaklı bir programlama dili. Python ile birlikte veri bilimi için en popüler dillerden biri.
- TinkerPlots, ilkokul ve ortaokul öğrencileri için bir EDA yazılımıdır.
- Weka, görselleştirme ve hedeflenen projeksiyon takibi gibi EDA araçlarını içeren açık kaynaklı bir veri madenciliği paketi.
Ayrıca bakınız
- Anscombe'un dörtlüsü, keşfin önemi üzerine
- Veri tarama
- Tahmine dayalı analitik
- Yapılandırılmış veri analizi (istatistikler)
- Yapısal frekans analizi
- Tanımlayıcı istatistikler
Kaynakça
- ^ Chatfield, Christopher (1995). Problem solving : a statistician's guide. 2nd ed. Londra: Chapman & Hall. ISBN 0-412-60630-5. OCLC 32881624.
- ^ a b Bowley, A. L. (Arthur Lyon) Sir (1920). An elementary manual of statisics. Cornell University Library. London, MacDonald and Evans.
- ^ Tukey, John W. (1 Mayıs 1991). "Data Analysis". Fort Belvoir, VA.
- ^ "Dış bağlantı". 10 Şubat 2006 tarihinde kaynağından arşivlendi.
- ^ Fernholz, Luisa T.; Morgenthaler, Stephan (1 Şubat 2000). "A conversation with John W. Tukey and Elizabeth Tukey". Statistical Science. 15 (1). doi:10.1214/ss/1009212675. ISSN 0883-4237. 24 Haziran 2021 tarihinde kaynağından arşivlendi. Erişim tarihi: 23 Haziran 2021.
- ^ Tukey, John W. (1977). Exploratory data analysis. Reading, Mass.: Addison-Wesley Pub. Co. ISBN 0-201-07616-0. OCLC 3058187.
- ^ "Behrens-Keşfedici Veri Analizinin İlke ve Prosedürleri-Amerikan Psikoloji Derneği-1997" (PDF). 8 Ağustos 2017 tarihinde kaynağından (PDF) arşivlendi. Erişim tarihi: 23 Haziran 2021.
- ^ Konold, Clifford. "Statistics Goes to School". Contemporary Psychology. 44 (1): 81-82. doi:10.1037/001949.
- ^ Tukey, John W. "We Need Both Exploratory and Confirmatory". The American Statistician (İngilizce). 34 (1): 23-25. doi:10.1080/00031305.1980.10482706. ISSN 0003-1305. 6 Haziran 2021 tarihinde kaynağından arşivlendi. Erişim tarihi: 23 Haziran 2021.
- ^ Sailem, Heba Z.; Sero, Julia E.; Bakal, Chris. "Visualizing cellular imaging data using PhenoPlot". Nature Communications (İngilizce). 6 (1): 5825. doi:10.1038/ncomms6825. ISSN 2041-1723. 19 Aralık 2020 tarihinde kaynağından arşivlendi. Erişim tarihi: 23 Haziran 2021.





