Olasılık kuramı ve istatistik bilim dallarında varyans bir rassal değişken, bir olasılık dağılımı veya örneklem için istatistiksel yayılımın, mümkün bütün değerlerin beklenen değer veya ortalamadan uzaklıklarının karelerinin ortalaması şeklinde bulunan bir ölçüdür. Ortalama bir dağılımın merkezsel konum noktasını bulmaya çalışırken, varyans değerlerin ne ölçekte veya ne derecede yaygın olduklarını tanımlamayı hedef alır. Varyans için ölçülme birimi orijinal değişkenin biriminin karesidir. Varyansın karekökü standart sapma olarak adlandırılır; bunun ölçme birimi orijinal değişkenle aynı birimde olur ve bu nedenle daha kolayca yorumlanabilir.
Regresyon analizi, iki ya da daha çok nicel değişken arasındaki ilişkiyi ölçmek için kullanılan analiz metodudur. Eğer tek bir değişken kullanılarak analiz yapılıyorsa buna tek değişkenli regresyon, birden çok değişken kullanılıyorsa çok değişkenli regresyon analizi olarak isimlendirilir. Regresyon analizi ile değişkenler arasındaki ilişkinin varlığı, eğer ilişki var ise bunun gücü hakkında bilgi edinilebilir. Regresyon terimi için öz Türkçe olarak bağlanım sözcüğü kullanılması teklif edilmiş ise de Türk ekonometriciler arasında bu kullanım yaygın değildir.
Hipotez testi, bir hipotezin doğruluğunun istatistiksel bir güvenilirlik aralığında saptanması için kullanılan yöntem.

Aritmetik ortalama, bir sayı dizisindeki elemanların toplamının eleman sayısına bölünmesi ile elde edilir. İstatistik bilim dalında hem betimsel istatistik alanında hem de çıkarımsal istatistik alanında en çok kullanan merkezi eğilim ölçüsü' dür.
Ortalama veya merkezsel konum ölçüleri, istatistik bilim dalında ve veri analizinde kullanılan bir veri dizisinin orta konumunu, tek bir sayı ile ifade eden betimsel istatistik ölçüsüdür. Günlük hayatta ortalama dendiğinde genellikle kast edilen aritmetik ortalama olmakla beraber bu ölçünün çok belirli bazı dezavantajları söz konusudur. Bu yüzden matematik ve istatistikte, bir anakütle veya örneklem veri dizisi değerlerini temsil eden tek bir orta değer veya beklenen değer, olarak medyan (ortanca), mod (tepedeğer), geometrik ortalama, harmonik ortalama vb adlari verilen birçok değişik merkezsel konum ölçüleri geliştirilmiş ve pratikte kullanılmaktadır.

Standart sapma, Olasılık kuramı ve istatistik bilim dallarında, bir anakütle, bir örneklem, bir olasılık dağılımı veya bir rassal değişken, veri değerlerinin yayılımının özetlenmesi için kullanılan bir ölçüdür. Matematik notasyonunda genel olarak, bir anakütle veya bir rassal değişken veya bir olasılık dağılımı için standart sapma σ ile ifade edilir; örneklem verileri için standart sapma için ise s veya s'
Harmonik ortalama, gözlem sonuçlarının terslerinin aritmetik ortalamasının tersidir.

Olasılık kuramı ve istatistik bilim dallarında geometrik dağılım şu iki şekilde ifade edilebilen ayrık olasılık dağılımıdır:
- Bütün tam sayılar setine, yani { 1, 2, 3, .... } üzerine, bağlı olarak X sayıda Bernoulli denemesinde ilk başarıyı elde etmenin olasılık dağılımı; veya
- Bütün tam sayılar setine, yani {1, 2,3, ....} üzerine, bağlı olarak ilk başarıyı elde etmeden Y = X − 1 başarısızlık sayısı olasılık dağılımı.

Çarpıklık olasılık kuramı ve istatistik bilim dallarında bir reel-değerli rassal değişkenin olasılık dağılımının simetrik olamayışının ölçülmesidir.
İstatistik bilim dalında, Spearman'ın sıralama korelasyon katsayısı veya Spearman'ın rho, bu istatistiksel ölçüyü ilk ortaya atan İngiliz psikolog Charles Edward Spearman'a atfen adlandırılmıştır. Matematik notasyon olarak çok defa eski Yunan harfi ρ ile belirtilir. Bir parametrik olmayan istatistik ölçüsüdür ve iki değişken arasındaki bağımlılık, yani korelasyon, ölçüsü olarak bulunup kullanılır. Bu demektir ki Spearman'in rho (ρ) katsayısı iki değişken için çokluluklar dağılımı hakkında hiçbir varsayım yapmayarak, bu iki değişken arasında bulunan bağlantının herhangi bir monotonik fonksiyon ile ne kadar iyi betimlenebilineceğini değerlendirmek amaçlı incelemedir.

Büyük Sayılar Kanunu ya da Büyük Sayılar Yasası, bir rassal değişkenin uzun vadeli kararlılığını tanımlayan bir olasılık teoremidir. Sonlu bir beklenen değere sahip birbirinden bağımsız ve eşit dağılıma sahip bir rassal değişkenler örneklemi verildiğinde, bu gözlemlerin ortalaması sonuçta bu beklenen değere yakınsayacak ve bu değere yakın bir seyir izleyecektir.
Klasik olarak üç değişik Pisagorik ortalama vardır: Bunlar aritmetik ortalama (A), geometrik ortalama (G) ve harmonik ortalama (H) olup şu formüller ile tanımlanılırlar.:
Bir genelleştirilmiş ortalama; Pisagorik ortalamalarını, yani aritmetik ortalama, geometrik ortalama ve harmonik ortalamayı, aynı tanım formülünde birleştirip kapsayan bir soyut genelleştirmedir. Güç ortalaması veya Holder ortalaması adları da verilmektedir.

Olasılık kuramı ve istatistik bilim dallarında log-normal dağılım logaritması normal dağılım gösteren herhangi bir rassal değişken için tek-kuyruklu bir olasılık dağılımdır. Eğer Y normal dağılım gösteren bir rassal değişken ise, bu halde X= exp(Y) için olasılık dağılımı bir log-normal dağılımdır; aynı şekilde eğer X log-normal dağılım gösterirse o halde log(X) normal dağılım gösterir. Logaritma fonksiyonu için bazın ne olduğu önemli değildir: Herhangi iki pozitif sayı olan a, b ≠ 1 için eğer loga(X) normal dağılım gösterirse, logb(X) fonksiyonu da normaldir.
İstatistik bilim dalında ağırlıklı ortalama betimsel istatistik alanında, genellikle örneklem, veri dizisini özetlemek için bir merkezsel konum ölçüsüdür. En çok kullanan ağırlıklı ortalama tipi ağırlıklı aritmetik ortalamadır. Burada genel olarak bir örnekle bu kavram açıklanmaktadır. Değişik özel tipli ağırlıklar alan özel ağırlıklı aritmetik ortalamalar bulunmaktadır. Diğer ağırlıklı ortalamalar ağırlıklı geometrik ortalama ve ağırlıklı harmonik ortalamadir. Ağırlıklı ortalama kavramı ile ilişkili teorik açıklamalar son kısımda ele alınacakdır.
Matematik ve istatistik bilim dallarında genelleştirilmiş f-ortalaması merkezsel konum ölçülerinden olan değişik ortalamalar için tek bir genel fonksiyon ve formül bulma ve kullanma çabaları sonucu ortaya çıkarılmıştır. Benzer çabalar biraz değişik diğer bir genelleştirilmiş ortalama formülünü vermiştir. Bu nedenle isim karışıklığını önlemek için f-ortalaması çeşitli diğer isimlerde de anılmaktadır. Bazen yarı-aritmetik ortalama adı kullanılmaktadır. Bu kavramı ve formülü ilk geliştiren Rus matematikçisi A.Kolmogorov adına atfen de bazen Kolmogorov ortalaması olarak isimlendirilmektedir.
F-testi istatistik bilimi içinde bir sıra değişik problemlerde kullanılan parameterik çıkarımsal sınama yöntemidir. F-testi sıfır hipotezine göre gerçekte bir F-dağılımı gösteren sınama istatistiği bulunduğu kabul edilen hallerde, herhangi bir istatistiksel sınama yapma şeklidir. Bu çeşit bir istatistiksel sınama önce Ronald Fisher tarafından 1920'li yıllarda tek yönlü varyans analizi için ortaya atılıp kullanılmış ve sonradan diğer şekillerde F-dağılım kullanan sınamalar da ortaya atılınca, bu çeşit sınamalara genel isim olarak F-testi adı verilmesi Ronald Fisher anısına George W. Snecedor tarafından teklif edilip, istatistikçiler tarafından F-testi bir genel isim olarak kabul edilmiştir.
Medyan bir anakütle ya da örneklem veri serisini küçükten büyüğe doğru sıraladığımızda, seriyi ortadan ikiye ayıran değere denir. İstatistiğin bir alt dalı olan betimsel istatistikde medyan bir merkezsel konum ölçüsü kabul edilir.
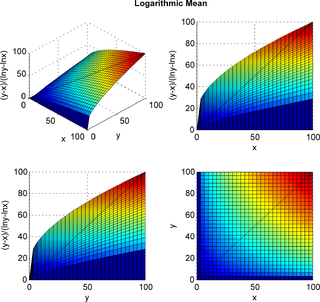
Matematikte logaritmik ortalama, iki pozitif gerçek sayının farkının bu sayıların doğal logaritmalarının farkına oranı olarak tanımlanır. Bu hesaplama, ısı ve kütle transferi içeren mühendislik problemlerinde kullanılabilir.
Matematikte Stolarsky ortalaması, logaritmik ortalamanın bir genelleştirmesidir. 1975 yılında Kenneth B. Stolarsky tarafından ortaya atılmıştır.



![{\displaystyle G={\sqrt[{n}]{x_{1}\cdot x_{2}\dotsb x_{n}}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/943ff0451c90823e9d27e5ef12dbacb47f4f5790)



