Anlamlılık seviyesi
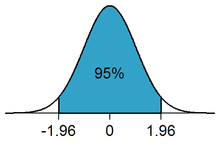
Anlamlılık seviyesi, istatistik biliminde, İngiliz istatistikçi Ronald Fisher tarafından çıkartımsal hipotez sınama yönteminin kurulması sırasında kavramlaştırılmış özel bir manası olan bir bilimsel ve istatistiksel terimdir. İstatistiksel anlamlılık eğer bir sonucun gerçekleşme olasılık değerlendirilmesine göre olabilirliği düşük değil ise ortaya çıkar.[1]
İstatistik teorisine göre açıklamalar
Anlamlılık istatistik biliminde özel bir manası olan ve daha komplike bir istatistik kavramını çok kısa olarak isimlendirilmek için kullanılan özel bir terimdir. Günlük dilde anlamlılık manası olan veya önemi olan lügat manasını taşımaktadır. İstatistiksel anlamlılık bu günlük anlamlılık manasına tam olarak eşit değildir; ve arkasında bir olasılık bulunan bir mana taşımaktadır. Ülkenin belirli bir bölgesinde uygulanan ve binlerce kişilik örneklemlere tatbik edilen bir zeka testinin sayısal sonuçlarını kullanılarak yapılan hesaplamalar sonunda elde edilen ortalama değerlere göre bir bölgenin ortalama zeka testi sonucu ile diğer bir bölgenin ortalama zeka testi sonucu arasında 1/20 bir fark olduğu %5 anlamlılık düzeyli hipotez sınaması ile ortaya çıkmış olsun. Bu çıkartımsal sonuç istatistiksel anlamlı olacaktır; fakat ortalamalar arasındaki 1/20 farkın alelade kullanılan dil anlamı ile pek önemli olmadığı gayet açıktır. Bu nedenle birçok bilimsel araştırmacılar istatiksel hipotez testleri analizde kullanıldığı zaman etki büyüklüğü istatistiğinde verilmesini ve böylelikle farkların pratik öneminin açıkça belirtilmesini çok sıkı olarak tavsiye etmektedirler.
Bir olayın ortaya çıkma şansının olasılığının çok küçük olduğunu kabul etmek için gereken kanıtların miktarı 'anlamlılık düzeyi veya kritik p-değeri olarak isimlendirilir. Geleneksel Fisher-tipi istatistiksel hipotez sınaması teorisi içinde p-değeri gözümlenen veriler veya daha çok dışsal veriler için sıfır hipotezin şartlı olasılığıdır. Eğer hesaplanan p-değeri küçükse, o zaman ya sıfır hipotez yanlıştır veya çok ender ve olağan olmayan bir olay ortaya çıkmıştır. Burada p-değerlerinin herhangi bir örneklem tekrarlanması yorumu olmadığını ve örneklem tekrarı gereğini ifade etmediğini vurgulamak gerekmektedir.
İstatistiksel hipotez sınaması çerçevesini Fisher-tipinden değişik açıklayan diğer bir felsefi temel de bulunmaktadır. Bu "Neyman-Pearson leması" adı altında olasılığın çokluluk temeline dayandıran felsefi açıklamanın bir gelişmesidir. Bu "çokluluk ekolü" açıklamasında, hem sıfır hem alternatif hipotez açıkça tanımlanmasını gerekmektedir ve bunun için gerekli örneklem tekrarlanması prosedürünün özellikleri incelenmektedir. Bu yaklaşım, "Hatalı pozitif" veya Tıp İ hata yani sıfır hipotezin gerçekte kabul edilmesi gerekirken bu hipotezin ret edilmesi olasılığı ile Tıp II hata yani sıfır hipotezin yanlış olup gerçekte ret edilmesi gerekirken o hipotezi kabul etme kararı olasılı karşılaştırılmasını önermektedir.
Tipik olarak bir hipotez sınaması "anlamlılık düzeyi", Tip İ hata yani kabul edilmesi gerekli bir doğru sıfır hipotezin ret edilmesi, olasılığının önceden seçilmiş bir olasılıktan daha fazla olmaması"dır. Böylece bazı enformasyon kullanılmayıp boşa gitmekle beraber hesaplama külfeti azaltılmakta ve testlerin anlamlılığı olmayan istatistikleri kullanarak gerçekleştirilmesine izin vermektedir.
Fisher tipi p-değerleri, Neyman-Pearson Tıp İ hatalardan felsefi olarak değişiktir. Bu değişikliğin anlaşılmaması bir hata olup ne yazık ki birçok istatistik ders kitabında bu eksiklik devam edip gitmektedir.[2]
Pratikte kullanış
Anlamlılık seviyesi notasyon olarak genellikle Yunan harfi alfa, α ile belirtilir. Pratikte çok popüler olarak kullanılan anlamlılık seviyesi %5 (0,05), %1 (0,01) ve %0,1 (0.001)'dir.
Eğer bir istatistiksel hipotez sınaması için hesaplamalar α-seviyesinden küçük olan bir p-değeri ortaya çıkarırsa, o zaman "sıfır hipotez" reddedilir. Bu türlü analiz sonuçları, pek teorik olmayan bir yaklaşımla, "istatistiksel olarak anlamsız" olarak nitelendirilir. Örneğin, eğer bir istatistik kullanıcı "bu olayın rastlantı olarak ortaya çıkma şansı binde birdir" diye bir sonuç verirse, bu daha formel olarak 0,001 istatistiksel anlamlılık olarak açıklanabilir. Anlamlılık seviyesi ne kadar düşük olursa, gereken kanıtın o kadar daha güçlü olması gerekmektedir.
İstatistiksel çalışmalarda anlamlılık seviyesinin seçilmesi araştırmacının keyfine bağlıdır ama geleneksel olarak birçok uygulamada seçilen anlamlılık seviyesi %5 olmaktadır ve buna tek neden sırf geleneksel kullanıştır.[3]
Bazı hallerde ise daha istatistiksel anlamlılık seviyesini (1 − α) kabul etmek daha uygun olur. Genellikle bir çalışmada kullanılan anlamlılık seviyesini tefsir etmek için istatistiksel sınamanın yapılma nedeninin iyice anlaşılmasını gerektirir.
Bazı bilim ve teknoloji alanlarında, örneğin nükleer ve parçacık fiziki uygulama alanlarında istatistiksel anlamlılık bir normal dağılım standart sapması olan "σ" (sigma) birimleri ile ifade edilir. Bu şekilde ifade edilen bir istatistiksel anlamlılık değeri olan

alfa α ile ifade edilen anlamlılık seviyesine şu hata fonksiyonu kullanılarak dönüştürülebilir:

Anlamlılık seviyesini σ ile ifade edilmesi bilimciler arasında çok popüler olarak olasılık ve belirsizliğin ölçülmesi için normal dağılımın kullanılmasına açıkça işaret etmektedir.
Bu kullanışa bir örneğine göre, bir teori bir parametrenin değerinin (diyelim) 100 olduğuna işaret etmekte ise ve deneyle ölçülen parametre değeri 109 ± 3 ise, o zaman bu sonucu açıklamak için ölçülmenin teorik tahminden "3σ sapma" ile ortaya çıktığı ifade edilir. Eğer aynı ölçüm α ile ifade edilmek istenirse ifadenin şekli şu olur: "Eğer teori doğru ise, bu deneysel ölçümün rastlantı olarak elde edilmesinin olasılığı
- 1 − erf(3/√2) = 0.0027
yani %0,27 olur.
İstatistiksel çalışmaların sonuçlarını bildirilmesi sırasında %5, %1 veya %0,1 gibi sabit olan anlamlılık seviyelerinin kullandıktan sonra sadece kullanılan anlamlılık seviyesi ve sıfır hipotezin kabul ve reddedildiğini açıklamak yıllardır yeterli bilgi olarak sayılmıştır. Ancak günümüzde bu çeşit açıklamaların yeterli olamadığı ve ancak açıklayıcı veri analizleri için uygun olacağı kabul edilmektedir. Günümüz için bir deneyin veya bir ciddi çalışmanın için kullanıla istatistiksel hipotez testlerinin en son sonuçları hakkında bilgi verilmekte iken hesaplanan p-değerin açıkça belirtilmesi tavsiye edilmektedir. Ayrıca bu p-değeri verildikten sonra bu değerin istatistiksel anlamlılığı olup olmadığı hakkında araştırmacı şahsi hükümü de belirtilmesi istenmektedir. Bu tavsiyenin ortay çıkmasının başlıca nedeninin, meta analizler denilen birçok değişik deney ve çalışmayı birlikte karşılaştırmalı olarak incelemesinin çok popüler olarak kullanılmaya başlanmasıdır; p-değeri ve analizci sonucu açıkça verilirse bunlara doğrudan doğruya ekstra çalışma yapılmadan meta-analize konulması mümkün olur.
Teorik ve pratik tenkitler ve sorunlar
Amerikan bilim araştırmacıları McCloskey ve Ziliak bu istatistiksel analamlılık kavramının bilim alanında çok ciddi hatalara yol açtığını ve bu nedenle kullanılmaması gereğini iddia etmektedirler. Bu kavrama dayanarak bir sonucu "anlamlığı yok" diye açıklamak, bunun "önemsiz" olmadığı anlamına gelmediğinin bilimcilerde bilinmesi gereğine ve bilinmezse hatalı hipotezlerin kabul edilmesine ve doğru hipotezlerin ret edilmesine yol açabileceğine işaret etmektedirler. Bu hatalı yaklaşımların çok olasılığı bulunduğu için bilimsel sosyetenin hipotez sınaması terimlerini kullanmamasının daha uygun olacağını iddia etmektedirler.[4]
Anlamlılık kavramının sinyal-gürültü oranı şeklinde tefsir edilmesi
İstatistiksel anlamlılık verilmiş bir sonuca olan güvenin belirtilmesi olarak da görülebilir. Karşılaştırmalarla ilgilenen bir çalışmada bu kavram karşılaştırılan grupların arasındaki göreli farka, ölçülmelerin miktarına ve ölçülmeyle ilişkili gürültüye bağlıdır. Diğer anlamla, belirli bir sonucun rastgele olmaması (yani bu sonucun sadece şansa bağlı olmaması) sinyal-gürültü oranına ve örneklem hacmine bağlıdır.
Bu matematiksel ifade edilirse, güven Sackett tarafından verilmiş şu formülle açıklanabilir: [5]

Biraz daha açıklığa kavuşturmak için bu formül şu tablo halinde de temsil edilebilir:
Güvenin, gürültü, sinyal ve örneklem hacmine bağlılığı (tablo şeklinde açıklama )
| Parametre | Parametre artması | Parametre azalışı |
|---|---|---|
| Gürültü | Güvenin azalışı | Güvenin artışı |
| Sinyal | Güvenin artışı | Güvenin azalışı |
| Örneklem hacmi | Güvenin artışı | Güvenin azalışı |
Bu sözcüklerle ifade edilirse, eğer gürültü düşükse ve/veya örneklem hacmi yüksekse ve/veya sinyala efekt hacmi büyükse, güvene bağımlılık yüksektir. Bir sonuç olarak güven (ve ona bağlı olan güven aralığı) sadece efekt hacmine "bağımlı değildir". Eğer örneklem hacmi yüksekse ve gürültü düşük ise, küçük bir efekt hacmi büyük güvenle ölçülebilir. Küçük bir efekt hacminin önemli olup olmadığı karşılaştırması yapılan olaylara bağlıdır.
Tıp bilimi alanında (rizikodaki küçük artışlarda yansıyan) küçük efekt hacmi çok kere kliniksel olarak ilgili görülmektedir ve çok kere (eğer büyük güven varsa) sağlanım kararlarına bir yol gösterici olarak kullanılırlar. Belirli bir sağlanımın değerli uğraşa olarak kabul edilip edilmeyeceği rizikolara, yararlarına ve maliyetlere bağlıdır.
Dipnotlar
- ^ "Bu türde kritik testler "anlamlılık testleri" olarak isimlendirilebilir. Bu türlü testlerin yapılması mümkün ise elde ettiğimiz ilk örneklem verilerinin, ikinci bir örneklem verilerinden anlamlı bir şekilde farklı olup olmadığını ortaya çıkartabiliriz. — Fisher, R.A. (1925). Statistical Methods for Research Workers, Edinburgh: Oliver and Boyd, say.43. (İngilizce)
- ^ Hubbard, Raymond ve Bayarri,M.J. P Values are not Error Probabılıties (P-değerleri hata olasılıkları değildir) 4 Eylül 2013 tarihinde Wayback Machine sitesinde arşivlendi.. Fisher işbat p-değeri ile Neyman-Pearson I. Tip hata seviyesi arasındaki farkları açıklama hedefli makale. (İngilizce) (Erişme:6.5.2010)
- ^ Stigler, S. (2008), "Fisher and the 5% level", Chance Cilt 21 no.4 say12 Şablon:Doi=10.1007/s00144-008-0033-3
- ^ Ziliak, Stephen ve McCloskey, Deirdre, (2008). The Cult of Statistical Significance: How the Standard Error Costs Us Jobs, Justice, and Lives[]. Ann Arbor, University of Michigan Press, 2009. (İngilizce) (Erişme:6.5.2010)
- ^ Sackett, D.L. (2001), "Why randomized controlled trials fail büt needn't: 2. Failüre to employ physiological statistics, or the only formula a clinician-trialist iş ever likely to need (or understand!)", CMAJ Cilt:165 No:9 Ekim, say.1226–37 {{|pmid=11706914 |pmc=81587 |doi= |url=http://www.cmaj.ca/cgı/pmıdlookup?view=long&pmid=11706914}} (İngilizce)

Ayrıca bakınız
- İstatistiksel hipotez sınaması
- A/B testi
- ABX testi
- İstatistiksel bağımsızlık ile klasik anlamlılık hipotez sınaması kavramlarını birleştiren "Fisher yaklaşımı"
- Makul şüphe
Dış bağlantılar
- İngilizce Wikipedia "Statistical significance" maddesi:[1] 16 Şubat 2010 tarihinde Wayback Machine sitesinde arşivlendi. (İngilizce) (Erişme:6.5.2010)
- Thompson, Bruce, (2004). "The 'significance' crisis in psychology and education." Journal of Soçio-Economics, Cilt 33, say. 607-613. (İngilizce) (Erişme:6.5.2010)
- İstatistikte 'anlamlılık' teriminin kullanılması tarihçesi. 3 Kasım 2017 tarihinde Wayback Machine sitesinde arşivlendi. (İngilizce) (Erişme:6.5.2010)
- İstatistiksel anlamlılık sınaması kavramının, sınav değerlendirmeleri konusu odaklı olarak açıklaması 2 Ekim 2010 tarihinde Wayback Machine sitesinde arşivlendi. (İngilizce) (Erişme:6.5.2010)
